Die Kostenseite Cloud-API: Was wirklich anfällt
Für gängige LLM-APIs gelten Mai 2026 folgende Größenordnungen:
| Modell | Input (pro 1M Token) | Output (pro 1M Token) |
|---|---|---|
| GPT-4o | ~5 $ | ~15 $ |
| Claude 3.5 Sonnet | ~3 $ | ~15 $ |
| Gemini 1.5 Pro | ~3,50 $ | ~10,50 $ |
| Mistral Large (API) | ~2 $ | ~6 $ |
Typische Anfrage: 500 Input-Token + 300 Output-Token = 800 Token gesamt.
Bei GPT-4o: ~0,006 $ pro Anfrage. Bei 100.000 Anfragen/Monat: ~600 €. Bei 1 Million Anfragen: ~6.000 € monatlich.
Dazu kommen: Embedding-Kosten für RAG-Systeme, Reranking-API-Aufrufe, Monitoring-Tools. In der Praxis rechnen Sie mit 20–40 % Aufschlag auf die reinen Token-Kosten.
Die Kostenseite On-Premise: Vollständige Kalkulation
Hardware (einmalig):
Laufende Kosten (monatlich):
Gesamt laufend: ~950–2.550 €/Monat
Bei 3 Jahren Abschreibung des Servers (30.000 €): ~830 €/Monat Kapitalkosten.
Total Cost of Ownership (TCO) pro Monat bei einem A100-Server: 1.800–3.400 €
- NVIDIA A100 80GB: 15.000–25.000 €
- NVIDIA H100 80GB: 30.000–40.000 €
- Server-Chassis, RAM, NVMe: 5.000–10.000 €
- Gesamt für einen A100-Server: 20.000–35.000 €
- Strom: ~400–600 kWh/Monat pro A100 → bei 0,30 €/kWh: ~150 € Strom
- Colocation oder eigener Serverraum: 200–500 €/Monat
- Wartung und IT-Personal (anteilig): 500–1.500 €/Monat
- Monitoring, Backup, Updates: 100–300 €/Monat
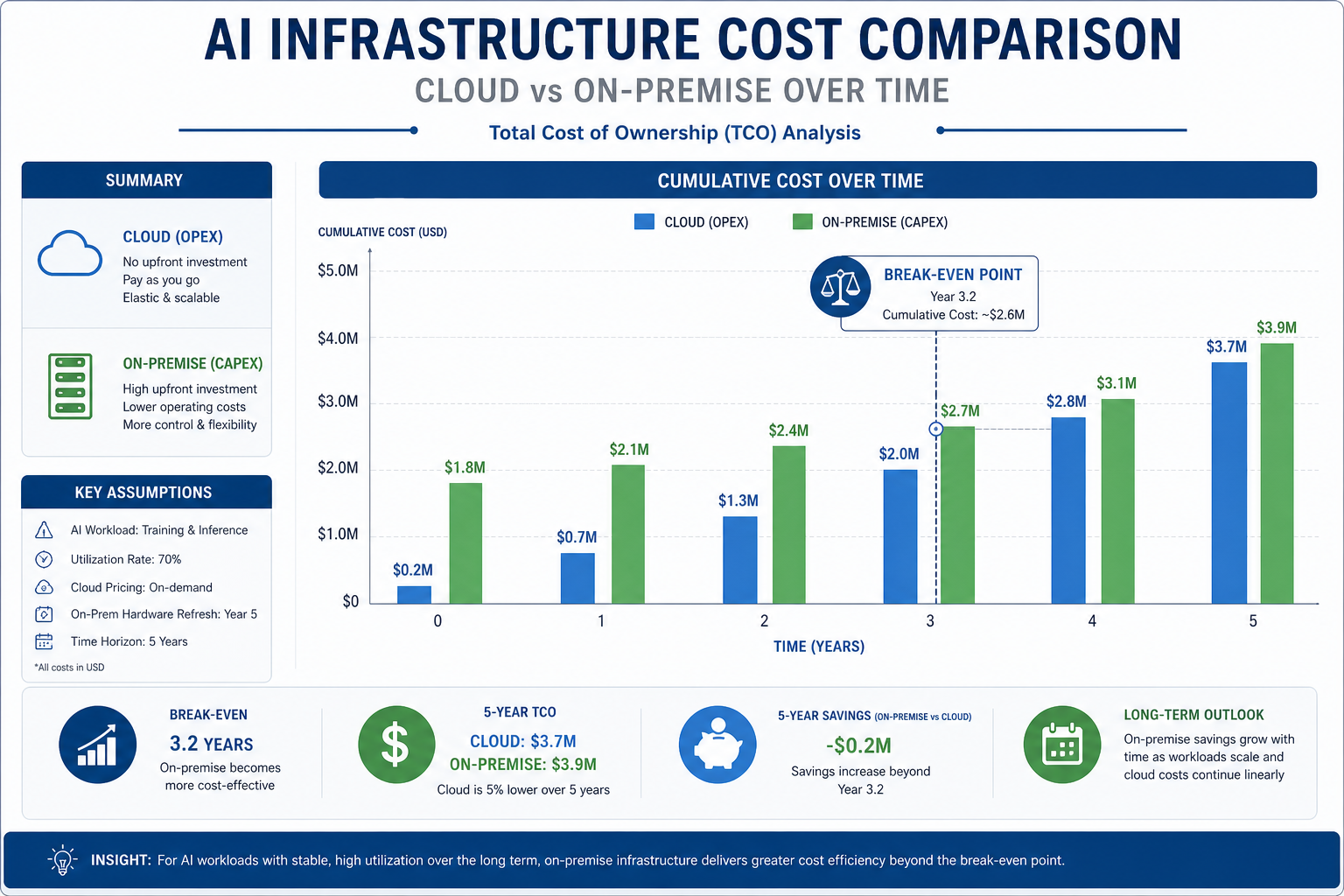
Break-Even-Analyse: Ab wann kippt die Rechnung
Bei einem TCO von ~2.500 €/Monat und Cloud-Kosten von 0,006 € pro Anfrage (GPT-4o):
2.500 € / 0,006 € = ~416.000 Anfragen/Monat
Nutzen Sie effizientere Modelle für die Cloud (z.B. Mistral API bei ~0,003 €/Anfrage):
2.500 € / 0,003 € = ~830.000 Anfragen/Monat
Faustregel: Unter 300.000 Anfragen/Monat ist Cloud meist günstiger. Ab 500.000–800.000 Anfragen/Monat lohnt On-Premise. Dazwischen: rechnen Sie durch.
Die oft übersehene dritte Option: EU-hosted Private Cloud
Zwischen "eigene Hardware" und "US-Cloud" gibt es eine dritte Variante, die viele Unternehmen 2026 wählen: dedizierte GPU-Kapazität bei deutschen oder europäischen Cloud-Anbietern.
Anbieter wie IONOS, Hetzner, OVHcloud oder Deutsche Telekom bieten GPU-Instanzen auf deutschen Servern: DSGVO-konform, mit AVV, ohne Datenabfluss in die USA. Kosten: 1,50–4 €/Stunde für A100-Klasse.
Vorteil: Kein Hardware-Invest, keine Wartung, DSGVO-konform, schnell skalierbar. Das ist für die meisten Mittelstandsunternehmen unter dem Break-Even die wirtschaftlichste Datenschutz-Lösung.
Meine Empfehlung nach Unternehmensgröße
Unter 100.000 Anfragen/Monat: EU-hosted Cloud (IONOS, Hetzner) oder Mistral/Claude API mit AVV. Kein Capex, volle Flexibilität.
100.000–500.000 Anfragen/Monat: EU-hosted dedizierte GPU-Instanz. Günstiger als US-Cloud, kein Hardware-Aufwand.
Über 500.000 Anfragen/Monat mit homogenen Use Cases: On-Premise-Investition rechnen. Unter 3 Jahren amortisiert sich ein A100-Server typischerweise.
Spezialfall, maximale Datensouveränität: On-Premise unabhängig vom Volumen, wenn gesetzliche oder vertragliche Anforderungen es erzwingen (z.B. Finanzdienstleistungen, Gesundheitswesen, Rüstung).
---
Vollständige Private-AI-Architektur: Modellauswahl, DSGVO-Compliance und Implementierungsschritte im Leitfaden: Private AI: KI ohne Cloud-Risiko, der Leitfaden für deutsche Unternehmen