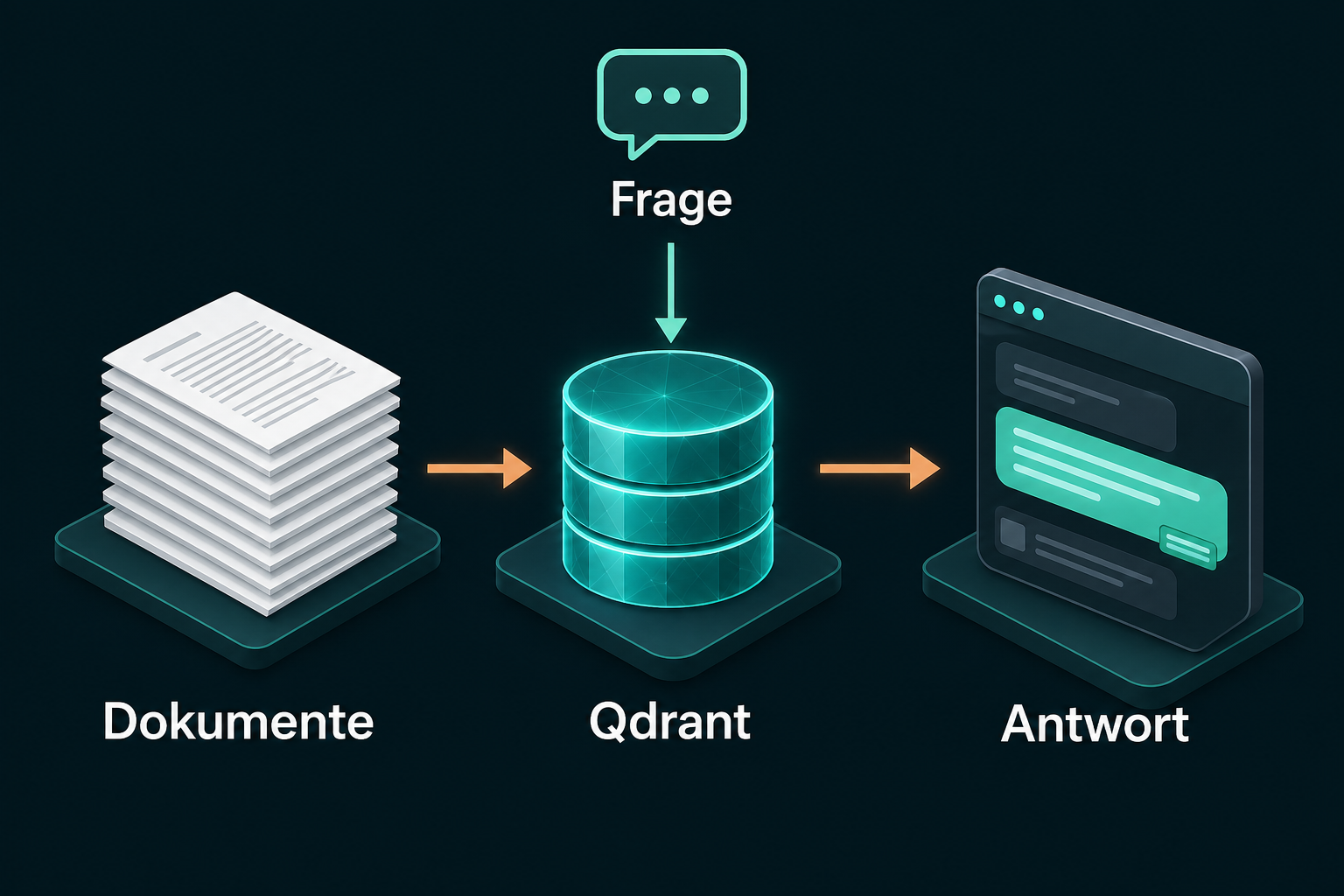
Welches RAG-System bauen Sie in diesem Tutorial?
Ein komplettes RAG-System auf Ihrem eigenen Rechner: Qdrant als Vektordatenbank im Docker-Container, Azure OpenAI für Embeddings und Antworten, dazu drei kurze TypeScript-Skripte für Ingest und Abfrage. Am Ende stellen Sie einer Wissensbasis aus Firmenrichtlinien Fragen auf Deutsch und bekommen Antworten mit Quellenangabe. Fragen, deren Antwort nicht in den Dokumenten steht, weist das System ab, statt zu halluzinieren.
RAG (Retrieval Augmented Generation) heißt: Das Sprachmodell antwortet nicht aus seinem Trainingswissen, sondern aus Ihren Dokumenten. Der Ablauf hat zwei Phasen. Beim Ingest zerlegen Sie Dokumente in Chunks, wandeln jeden Chunk mit einem Embedding-Modell in einen Vektor um und speichern ihn in Qdrant. Bei der Abfrage wird die Frage ebenfalls zum Vektor, Qdrant liefert die ähnlichsten Chunks zurück, und das Chat-Modell formuliert daraus eine belegte Antwort.
Stand Juli 2026. Jedes Code-Beispiel in diesem Tutorial habe ich am 05.07.2026 real ausgeführt, mit diesen Versionen: Qdrant 1.18.2, Node.js 25, openai 6.45.0, @qdrant/js-client-rest 1.18.0, dazu text-embedding-3-large und gpt-5.4-mini als Azure-OpenAI-Deployments. Die zitierten Ausgaben habe ich direkt aus dem Terminal kopiert. Dieselbe Kombination aus Azure OpenAI und Qdrant trägt auch mein RAG Starter Kit, ein Laravel-Produkt mit über 500 Tests. Vieles von dem, was ich dort auf die harte Tour gelernt habe, steckt in den Hinweisen dieses Tutorials.
Schritt 1: Qdrant lokal mit Docker starten
Qdrant ist eine Open-Source-Vektordatenbank aus Berlin, geschrieben in Rust. Für den Einstieg reicht ein Docker-Container:
docker run -d --name qdrant -p 6333:6333 -p 6334:6334 \
-v "$(pwd)/qdrant_storage:/qdrant/storage:z" \
qdrant/qdrantPort 6333 ist die REST-API samt Web-UI, Port 6334 die gRPC-Schnittstelle. Das Volume sorgt dafür, dass Ihre Vektoren einen Container-Neustart überleben. Ob alles läuft, prüfen Sie mit einem Aufruf auf die Wurzel-Route:
curl http://localhost:6333/Die Antwort bei mir: {"title":"qdrant - vector search engine","version":"1.18.2"}. Unter http://localhost:6333/dashboard gibt es zusätzlich eine kleine Web-Oberfläche, in der Sie später Ihre Collection und die gespeicherten Punkte inspizieren können. Die Details zum Setup stehen im offiziellen Qdrant-Quickstart.
Schritt 2: Azure-OpenAI-Modelle bereitstellen
Sie brauchen zwei Modell-Deployments: ein Embedding-Modell und ein Chat-Modell. Falls noch keine Azure-OpenAI-Ressource existiert, legen Sie eine an (dieser Befehl ist als einziger im Tutorial nicht real gelaufen, sondern gegen die Azure-CLI-Hilfe geprüft, weil ich meine bestehende Ressource weiterverwendet habe):
az cognitiveservices account create \
--name mein-rag-projekt --resource-group rg-rag-tutorial \
--kind AIServices --sku S0 --location swedencentral \
--custom-domain mein-rag-projektDanach die beiden Deployments:
az cognitiveservices account deployment create \
--name mein-rag-projekt --resource-group rg-rag-tutorial \
--deployment-name text-embedding-3-large \
--model-name text-embedding-3-large --model-version "1" \
--model-format OpenAI --sku-name GlobalStandard --sku-capacity 1
az cognitiveservices account deployment create \
--name mein-rag-projekt --resource-group rg-rag-tutorial \
--deployment-name gpt-5.4-mini \
--model-name gpt-5.4-mini --model-version "2026-03-17" \
--model-format OpenAI --sku-name GlobalStandard --sku-capacity 1Ein Wort zur Region und zum Datenschutz, weil hier viele Tutorials schweigen: Der Deployment-Typ entscheidet, wo Ihre Daten verarbeitet werden. GlobalStandard speichert zwar at rest in der Ressourcen-Region, darf Anfragen aber laut Microsoft-Dokumentation zu Deployment-Typen in jeder Azure-Region weltweit verarbeiten. Wer EU-Verarbeitung braucht, wählt DataZoneStandard (EU Data Boundary, Stand Mai 2026 Rechenzentren in 9 Ländern, darunter Deutschland und Schweden) oder den regionalen Standard-SKU. Die Verfügbarkeit unterscheidet sich je Modell: In Germany West Central habe ich per az cognitiveservices model list geprüft, dass text-embedding-3-large dort als Standard und DataZoneStandard verfügbar ist, gpt-5.4-mini im Pay-as-you-go-Modell dagegen nur als GlobalStandard. Nach dem Rechts-Audit meines RAG Starter Kits im Juni 2026 habe ich dort deshalb einen Region-Check eingebaut, der in Produktion den Start verweigert, wenn eine Nicht-EU-Region konfiguriert ist. Prüfen Sie das früh, nicht nach dem Go-live.
Zum Schluss holen Sie den API-Key und setzen zwei Umgebungsvariablen:
az cognitiveservices account keys list \
--name mein-rag-projekt --resource-group rg-rag-tutorial \
--query key1 --output tsv
export AZURE_OPENAI_BASE_URL="https://mein-rag-projekt.cognitiveservices.azure.com/openai/v1/"
export AZURE_OPENAI_API_KEY="<Ihr Key aus dem Befehl darüber>"Das /openai/v1/ am Ende ist kein Tippfehler. Seit August 2025 gibt es die v1-API von Azure OpenAI: Sie nutzen den ganz normalen OpenAI-Client, ohne api-version-Parameter und ohne Azure-Spezialklassen. Die Umstellung ist in der offiziellen API-Lifecycle-Doku beschrieben. Den exakten Endpoint Ihrer Ressource zeigt az cognitiveservices account show --query properties.endpoint.
Schritt 3: Node-Projekt anlegen und Collection erstellen
Jetzt zum Code. Ein frisches Node-Projekt mit zwei Abhängigkeiten genügt:
mkdir rag-tutorial && cd rag-tutorial
npm init -y
npm install openai @qdrant/js-client-rest
npm install -D typescript tsx @types/nodeBei mir installierte das openai 6.45.0 und @qdrant/js-client-rest 1.18.0. Die erste Datei legt die Collection an, also den Speicherort für Ihre Vektoren:
import { QdrantClient } from "@qdrant/js-client-rest";
const qdrant = new QdrantClient({ url: "http://localhost:6333" });
async function main() {
await qdrant.createCollection("wissensbasis", {
vectors: { size: 3072, distance: "Cosine" },
});
console.log("Collection wissensbasis angelegt.");
}
main().catch((fehler) => {
console.error(fehler);
process.exit(1);
});Die 3072 kommt direkt vom Modell: text-embedding-3-large liefert Vektoren mit exakt 3072 Dimensionen, und die Collection muss darauf passen. Legen Sie sie mit 1536 an (der Dimension des kleineren text-embedding-3-small), lehnt Qdrant später jeden Upsert mit einer Dimensions-Fehlermeldung ab. Als Distanzmaß ist Cosine für OpenAI-Embeddings die übliche Wahl. Speichern Sie die Datei als create-collection.ts und führen Sie sie aus:
npx tsx create-collection.tsAuf der Konsole erscheint Collection wissensbasis angelegt.
Schritt 4: Dokumente einbetten und speichern
Beim Ingest passiert die eigentliche Arbeit. Für das Tutorial dienen drei fiktive Firmenrichtlinien als Wissensbasis, im echten Projekt hängen Sie hier Ihre Dokumenten-Quelle an. Die Datei ingest.ts:
import { OpenAI } from "openai";
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new OpenAI({
baseURL: process.env.AZURE_OPENAI_BASE_URL,
apiKey: process.env.AZURE_OPENAI_API_KEY,
});
const qdrant = new QdrantClient({ url: "http://localhost:6333" });
const dokumente = [
{
quelle: "urlaubsrichtlinie.md",
text: `Alle Mitarbeitenden der Beispiel GmbH haben Anspruch auf 30 Tage Urlaub pro Kalenderjahr. Resturlaub verfällt nicht automatisch, muss aber bis zum 31. März des Folgejahres genommen werden. Urlaubsanträge laufen über das HR-Portal und brauchen die Freigabe der Teamleitung. Bei mehr als 10 zusammenhängenden Urlaubstagen ist eine Vorlaufzeit von 4 Wochen einzuhalten.`,
},
{
quelle: "homeoffice-regelung.md",
text: `Mitarbeitende können bis zu 3 Tage pro Woche im Homeoffice arbeiten. Dienstag ist verpflichtender Bürotag für alle Teams. Die Ausstattung des Heimarbeitsplatzes (Monitor, Tastatur, Stuhl) übernimmt die Firma bis zu einer Grenze von 800 Euro. Für Auslandsaufenthalte über 2 Wochen ist vorab die Zustimmung von HR nötig, weil steuerliche und sozialversicherungsrechtliche Fragen zu klären sind.`,
},
{
quelle: "spesenrichtlinie.md",
text: `Dienstreisen müssen vor Antritt im Reisetool angemeldet werden. Die Firma erstattet Bahnfahrten in der 2. Klasse, Flüge nur bei Strecken über 600 Kilometer. Die Verpflegungspauschale beträgt 28 Euro pro vollem Reisetag. Hotelkosten werden bis 150 Euro pro Nacht übernommen, in München und Hamburg bis 180 Euro. Belege sind innerhalb von 30 Tagen einzureichen.`,
},
];
function chunken(text: string, maxZeichen = 800): string[] {
const saetze = text.split(/(?<=[.!?])\s+/);
const chunks: string[] = [];
let aktuell = "";
for (const satz of saetze) {
if ((aktuell + " " + satz).length > maxZeichen && aktuell !== "") {
chunks.push(aktuell.trim());
aktuell = satz;
} else {
aktuell = aktuell === "" ? satz : aktuell + " " + satz;
}
}
if (aktuell.trim() !== "") chunks.push(aktuell.trim());
return chunks;
}
async function main() {
let id = 1;
for (const dokument of dokumente) {
for (const chunk of chunken(dokument.text)) {
const antwort = await client.embeddings.create({
model: "text-embedding-3-large",
input: chunk,
});
await qdrant.upsert("wissensbasis", {
wait: true,
points: [
{
id: id,
vector: antwort.data[0].embedding,
payload: { text: chunk, quelle: dokument.quelle },
},
],
});
console.log(`Chunk ${id} aus ${dokument.quelle} gespeichert.`);
id = id + 1;
}
}
}
main().catch((fehler) => {
console.error(fehler);
process.exit(1);
});Die Chunking-Funktion schneidet an Satzgrenzen und füllt bis maximal 800 Zeichen auf. Das ist bewusst schlicht gehalten. Für Richtlinien-Texte funktioniert es erstaunlich gut, für verschachtelte PDFs mit Tabellen brauchen Sie später mehr (Überschriften-basiertes Chunking, Overlap, Metadaten je Abschnitt). Im Payload landet neben dem Text auch die Quelle, damit die Antwort später belegen kann, woher sie ihr Wissen hat.
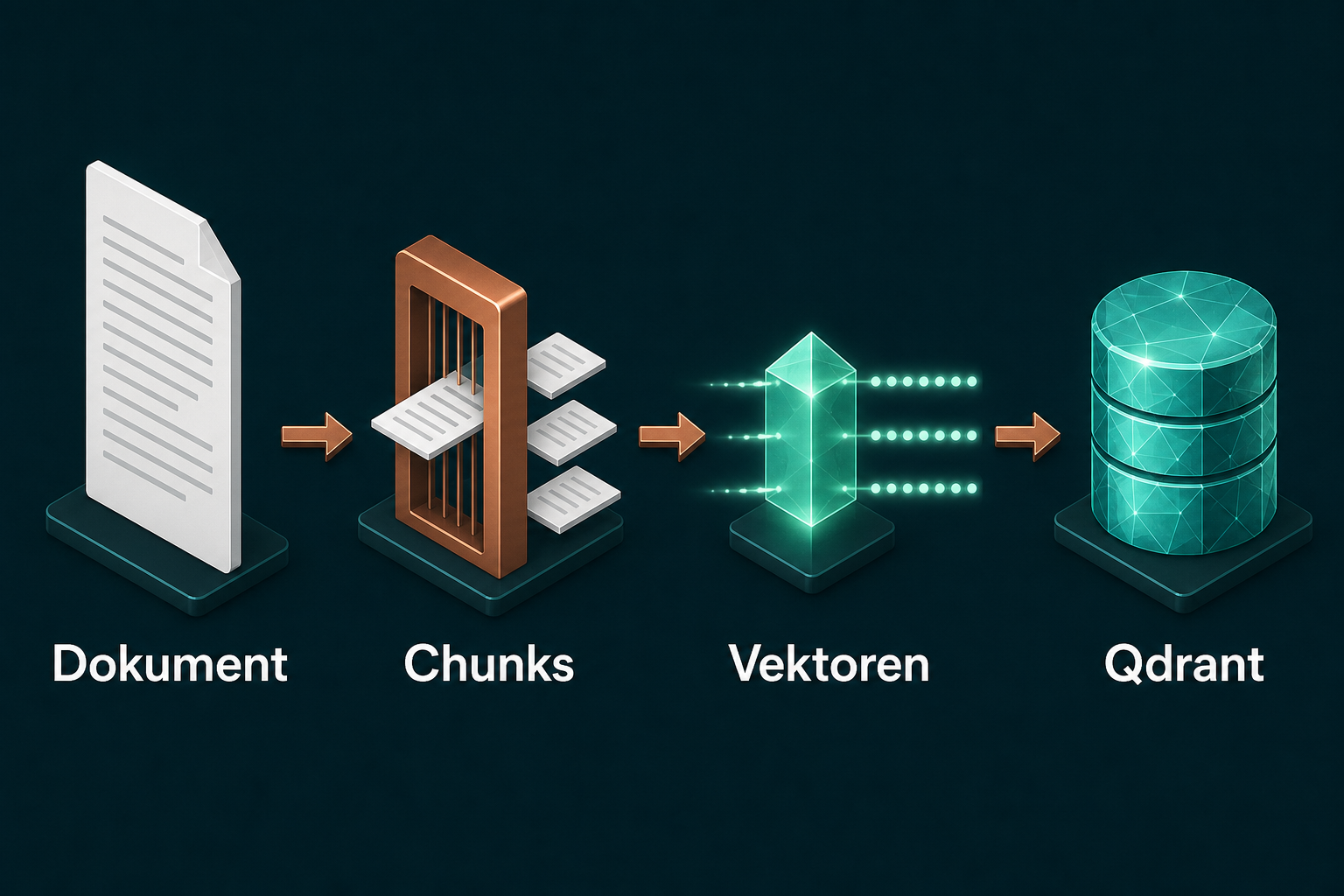
Ein Hinweis aus der Praxis: In diesem Tutorial landet der Chunk-Text direkt im Qdrant-Payload, weil das den Einstieg einfach macht. In meinem RAG Starter Kit habe ich mich dagegen entschieden. Dort hält Qdrant keinen Rohtext, sondern nur IDs und Metadaten, der Text kommt zur Antwortzeit aus der Primärdatenbank. Bei sensiblen Daten trennt das die Zugriffskontrolle sauber von der Ähnlichkeitssuche. Der Lauf selbst:
npx tsx ingest.tsBei mir liefen drei Zeilen durch, von Chunk 1 aus urlaubsrichtlinie.md gespeichert. bis Chunk 3 aus spesenrichtlinie.md gespeichert., weil jede der kurzen Richtlinien in einen einzelnen Chunk passt.
Schritt 5: Fragen stellen mit Retrieval und Chat-Modell
Die Abfrage-Seite dreht den Ingest um: Frage einbetten, in Qdrant die drei ähnlichsten Chunks suchen, dem Chat-Modell als Kontext geben. So sieht ask.ts aus:
import { OpenAI } from "openai";
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new OpenAI({
baseURL: process.env.AZURE_OPENAI_BASE_URL,
apiKey: process.env.AZURE_OPENAI_API_KEY,
});
const qdrant = new QdrantClient({ url: "http://localhost:6333" });
async function main() {
const frage = process.argv[2] ?? "Wie viele Urlaubstage habe ich?";
const frageVektor = await client.embeddings.create({
model: "text-embedding-3-large",
input: frage,
});
const treffer = await qdrant.query("wissensbasis", {
query: frageVektor.data[0].embedding,
limit: 3,
with_payload: true,
});
const kontext = treffer.points
.map((punkt) => `[${punkt.payload?.quelle}] ${punkt.payload?.text}`)
.join("\n\n");
const antwort = await client.chat.completions.create({
model: "gpt-5.4-mini",
messages: [
{
role: "system",
content:
"Du beantwortest Fragen ausschließlich auf Basis des mitgelieferten Kontexts. " +
"Nenne die Quelle in Klammern. Steht die Antwort nicht im Kontext, " +
"sage: Dazu finde ich nichts in der Wissensbasis.",
},
{
role: "user",
content: `Kontext:\n${kontext}\n\nFrage: ${frage}`,
},
],
});
console.log("Frage:", frage);
console.log("Antwort:", antwort.choices[0].message.content);
}
main().catch((fehler) => {
console.error(fehler);
process.exit(1);
});Zwei Details verdienen einen Blick. Erstens läuft die Suche über qdrant.query, die universelle Query-API des JS-Clients, mit with_payload: true, damit Text und Quelle mitkommen. Zweitens erzwingt der System-Prompt eine Ausweich-Antwort für Wissenslücken. Ohne diese Anweisung greift das Modell bei fehlendem Kontext auf sein Trainingswissen zurück und erfindet plausibel klingende Richtlinien. Das zu verhindern ist der ganze Sinn eines RAG-Systems.

Der erste echte Lauf:
npx tsx ask.ts "Wie viele Urlaubstage habe ich und was passiert mit Resturlaub?"Die Antwort meines Systems: „Alle Mitarbeitenden haben Anspruch auf 30 Tage Urlaub pro Kalenderjahr. Resturlaub verfällt nicht automatisch, muss aber bis zum 31. März des Folgejahres genommen werden. (urlaubsrichtlinie.md)“. Beide Fakten stimmen, die Quelle ist benannt.
Schritt 6: Ergebnis prüfen und typische Fehler vermeiden
Testen Sie jetzt den Fall, der scheitern muss. Fragen Sie etwas, das nicht in der Wissensbasis steht:
npx tsx ask.ts "Wie lautet das WLAN-Passwort im Büro?"Mein System antwortet: „Dazu finde ich nichts in der Wissensbasis.“ Genau so soll es sein. Ein System, das stattdessen eine plausible Spesenregel erfindet, richtet mehr Schaden an, denn der Fehler fällt erst auf, wenn sich jemand darauf verlassen hat. Sammeln Sie solche Grenzfragen von Anfang an, denn mit ihnen merken Sie sofort, wenn das System zu raten beginnt.
Beim Nachbauen werden Ihnen vermutlich ein paar Klassiker begegnen. Diese vier haben mich selbst Zeit gekostet:
| Fehler | Ursache | Lösung |
|---|---|---|
Bad Request: Vector dimension error beim Upsert | Collection-Dimension passt nicht zum Embedding-Modell | Collection mit 3072 für text-embedding-3-large anlegen |
401 Unauthorized bei Azure-Aufrufen | Key oder Endpoint falsch, /openai/v1/ fehlt | Endpoint per az cognitiveservices account show prüfen |
Cannot find name 'process' beim Typecheck | tsc kennt die Node-Typen nicht | @types/node installieren und beim direkten tsc-Aufruf --types node setzen |
| Modell antwortet aus Trainingswissen statt aus Dokumenten | System-Prompt erzwingt keine Kontext-Bindung | Ausweich-Antwort im System-Prompt vorschreiben und mit Grenzfragen testen |
Was Sie jetzt haben und wie es weitergeht
Sie haben ein lauffähiges RAG-System aus drei Skripten: Collection anlegen, Dokumente einbetten, Fragen beantworten. Es antwortet belegt mit Quellenangabe und passt bei Wissenslücken. Das ist der technische Kern, den auch große Systeme teilen.
Der Weg zum Produktivsystem führt über vier Baustellen, die dieses Tutorial bewusst ausgeklammert hat. Echte Dokumenten-Pipelines (PDF, Word, Confluence) mit strukturbewusstem Chunking. Hybrid Search, also die Kombination aus Vektor- und Keyword-Suche, die Qdrant über die Query-API mitbringt. Ein Eval-Set mit 30 bis 100 Referenzfragen inklusive Grenzfragen, bevor irgendetwas live geht. Und der rechtliche Rahmen: Deployment-Typ und Region wie in Schritt 2 beschrieben, ein Auftragsverarbeitungsvertrag mit Microsoft, und sobald Endnutzer mit dem System chatten, die KI-Kennzeichnung nach Artikel 50 der KI-Verordnung, die ab dem 02.08.2026 verpflichtend ist.
Wie ein solches System im Unternehmenskontext aussieht, samt Datenanbindung und Mandantentrennung, beschreibe ich in RAG und Wissenssysteme. Die strategische Einordnung, wann sich RAG gegenüber Feintuning und klassischer Suche lohnt, finden Sie im Artikel RAG-Systeme im Unternehmen und im Themen-Hub Private AI. Und wenn Ihr System irgendwann selbst entscheiden soll, wann es sucht und wie oft, lesen Sie in Agentic RAG weiter.
FAQ
Häufige Fragen
Warum Qdrant und nicht Azure AI Search?
Qdrant ist Open Source, läuft lokal im Docker-Container und kostet in dieser Form nichts. Für Prototypen und selbst gehostete Systeme ist das die flexibelste Wahl, und der Wechsel auf Qdrant Cloud oder einen eigenen Cluster ist später ein Konfigurationswechsel. Azure AI Search ist die richtige Wahl, wenn Sie ohnehin tief im Azure-Ökosystem stecken und Features wie integrierte Indexer über den Preis stellen.
Funktioniert das Tutorial auch mit Python?
Ja, die Architektur ist identisch. Die v1-API von Azure OpenAI nutzt auch in Python den Standard-OpenAI-Client mit base_url auf /openai/v1/, und Qdrant bietet mit qdrant-client eine gleichwertige Python-Bibliothek. Die drei Skripte lassen sich nahezu eins zu eins übertragen.
Was kostet der Betrieb dieses Setups?
Qdrant läuft lokal kostenlos. Bei Azure OpenAI zahlen Sie im GlobalStandard-Deployment pro Token, ohne Grundgebühr. Für alle Läufe dieses Tutorials (drei Dokumente einbetten, mehrere Fragen) sind bei mir nur Cent-Beträge angefallen. Relevante Kosten entstehen erst im laufenden Betrieb und bei wachsenden Datenmengen.
Wie kommen echte PDFs und Word-Dokumente in die Wissensbasis?
Vor das Chunking gehört ein Parsing-Schritt, der Text und Struktur extrahiert, etwa mit pdf-parse für Node oder Azure Document Intelligence für komplexe Layouts mit Tabellen. Danach bleibt die Pipeline gleich: chunken, einbetten, upserten. Investieren Sie hier zuerst in saubere Extraktion. Wenn schon aus dem PDF nur Textbrei ankommt, hat die beste Suche danach keine Chance mehr.
Ist dieses Setup DSGVO-konform?
Es ist DSGVO-konform betreibbar, aber nicht automatisch konform. Entscheidend sind der Deployment-Typ (EU-Verarbeitung über DataZone- oder regionale Standard-Deployments statt GlobalStandard), ein Auftragsverarbeitungsvertrag mit Microsoft und die Frage, welche personenbezogenen Daten überhaupt in die Wissensbasis gelangen. Mein Rat aus dem Audit meines eigenen Produkts: Rohtext und personenbezogene Daten so früh wie möglich aus dem Vektorspeicher heraushalten.