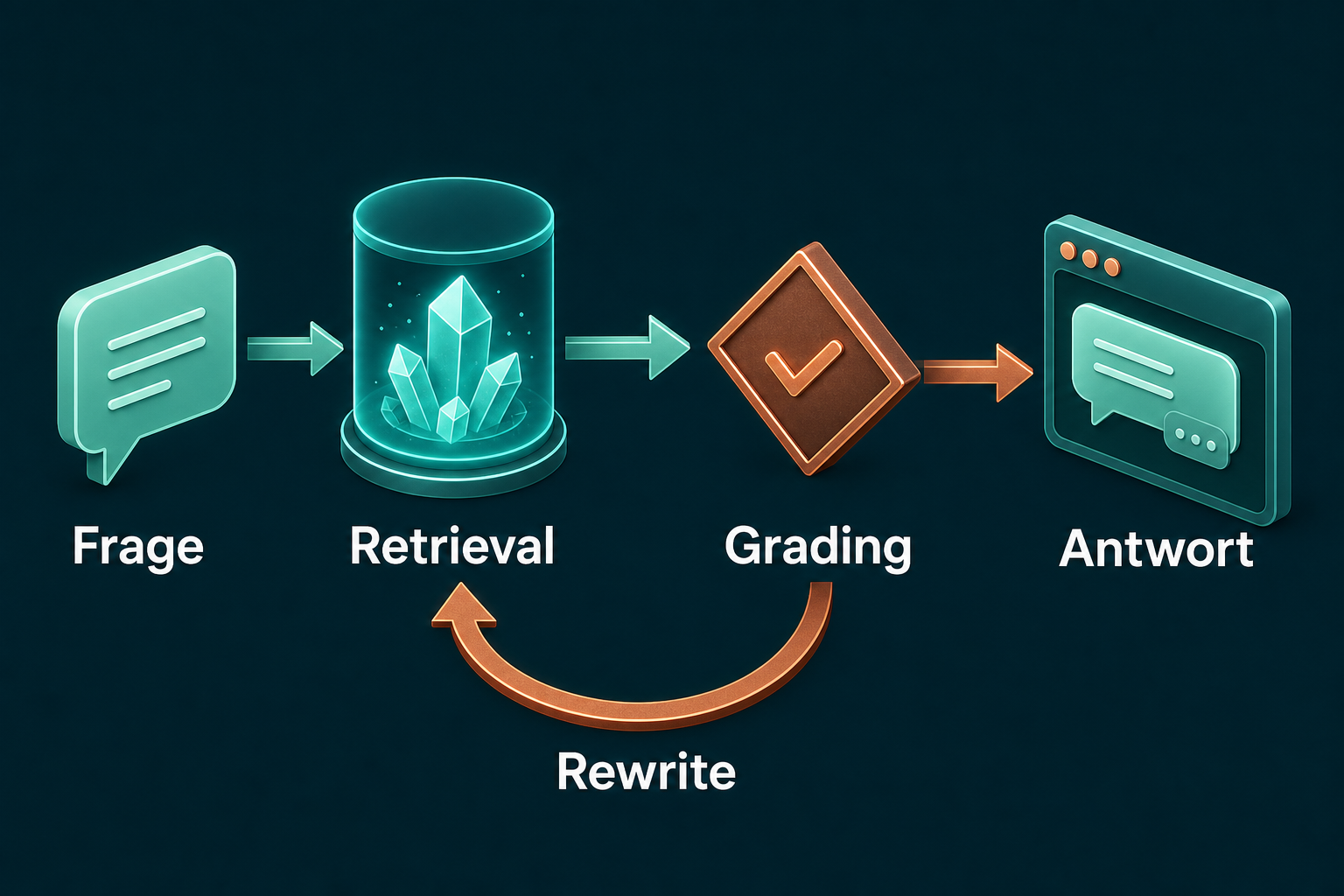
Was baut dieses Tutorial aus klassischem RAG heraus?
Sie erweitern ein klassisches RAG-System um eine Korrektur-Schleife: Statt aus dem ersten Suchergebnis zu antworten, bewertet ein Grader die gefundenen Textstellen, formuliert bei schwachen Belegen die Suchanfrage neu und sucht erneut. Erst wenn die Belege tragen, wird geantwortet. Findet die Schleife nach mehreren Anläufen nichts Passendes, sagt das System ehrlich ab, statt zu halluzinieren. Der Stack bleibt der gleiche wie im Grundlagen-Tutorial: Azure OpenAI für Embeddings, Grading und Antwort, Qdrant als Vektordatenbank, alles in TypeScript.
Agentic RAG heißt: Ein Sprachmodell steuert den Ablauf, statt ihn stur abzuspulen. Klassisches RAG ist linear, einmal suchen, einmal antworten. Agentic RAG ist eine Schleife mit Selbstkorrektur, angelehnt an das Verfahren Corrective RAG (CRAG). Der Kern ist ein zusätzlicher Schritt zwischen Suche und Antwort, das Grading. Der Grader prüft: Belegen die Treffer die Frage? Wenn nein, schreibt er die Suchanfrage um und schickt sie zurück in die Suche. Diese eine Rückkopplung entscheidet, ob Ihr System bei einer schlecht formulierten Frage aufgibt oder sich selbst korrigiert.
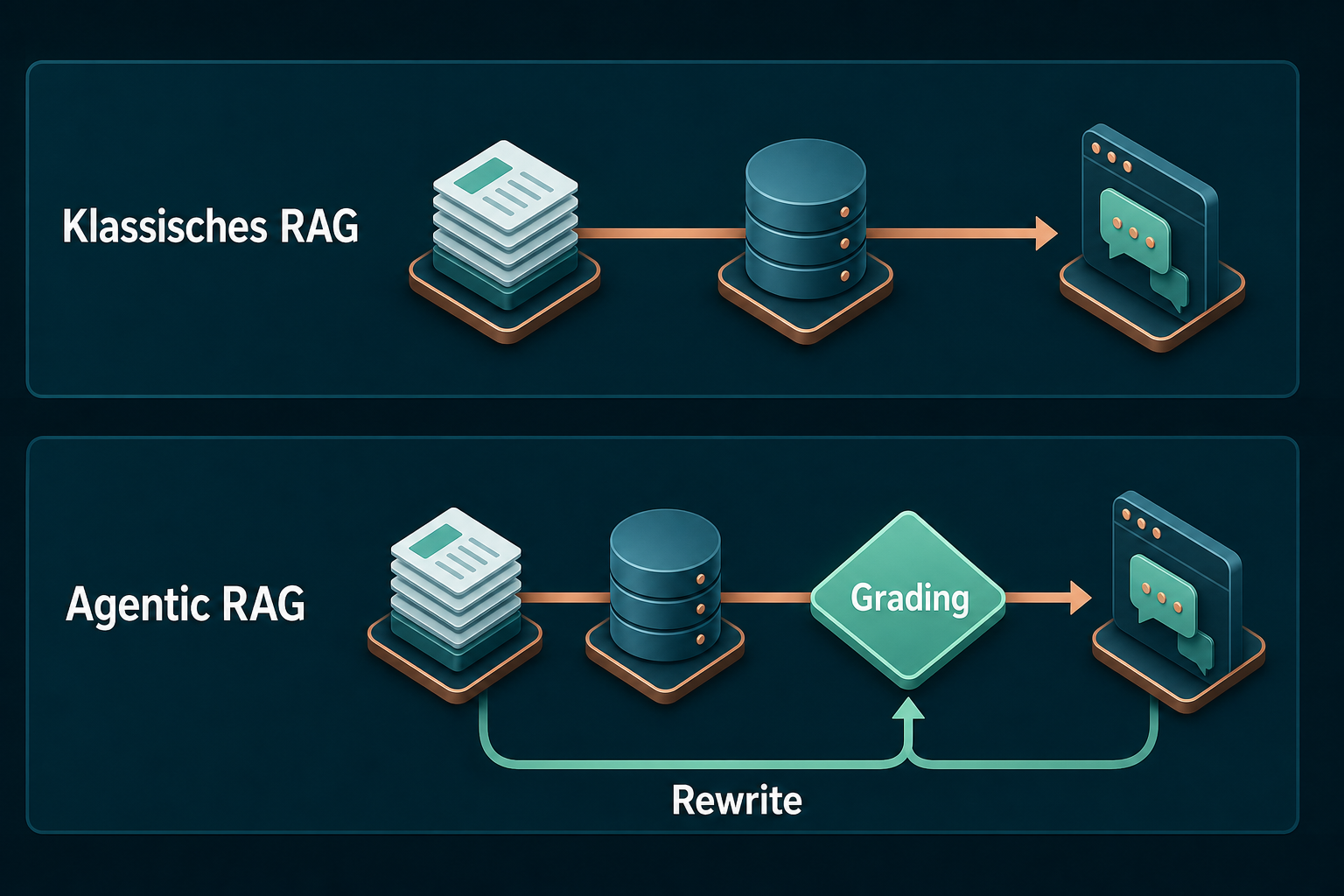
Stand Juli 2026. Jedes Code-Beispiel habe ich am 05.07.2026 real ausgeführt, mit diesen Versionen: Qdrant 1.18.2, Node.js 25, openai 6.45.0, @qdrant/js-client-rest 1.18.0, dazu text-embedding-3-large und gpt-5.4-mini als Azure-OpenAI-Deployments. Die zitierten Konsolen-Ausgaben stammen direkt aus dem Terminal, inklusive der beiden Kalibrierungs-Fehler, die mich beim Bauen Zeit gekostet haben. Dieses Tutorial setzt das Grundlagen-Tutorial zum RAG-System mit Azure OpenAI und Qdrant voraus, den konzeptionellen Hintergrund vertieft der Artikel Agentic RAG.
Schritt 1: Die Wissensbasis für die Schleife vorbereiten
Damit das Grading etwas zu bewerten hat, braucht die Wissensbasis mehrere thematisch getrennte Dokumente. Ich nehme fünf kurze Handbuch-Auszüge einer fiktiven Firma: Urlaub, Homeoffice, Spesen, IT-Sicherheit und Weiterbildung. Das Setup ist identisch zum Grundlagen-Tutorial, nur die Collection heißt jetzt wissensbasis-agentic. Die Datei ingest-agentic.ts:
import { OpenAI } from "openai";
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new OpenAI({
baseURL: process.env.AZURE_OPENAI_BASE_URL,
apiKey: process.env.AZURE_OPENAI_API_KEY,
});
const qdrant = new QdrantClient({ url: "http://localhost:6333" });
const dokumente = [
{ quelle: "urlaubsrichtlinie.md", text: `Alle Mitarbeitenden der Beispiel GmbH haben Anspruch auf 30 Tage Urlaub pro Kalenderjahr. Resturlaub verfällt nicht automatisch, muss aber bis zum 31. März des Folgejahres genommen werden. Urlaubsanträge laufen über das HR-Portal und brauchen die Freigabe der Teamleitung.` },
{ quelle: "homeoffice-regelung.md", text: `Mitarbeitende können bis zu 3 Tage pro Woche im Homeoffice arbeiten. Dienstag ist verpflichtender Bürotag. Die Ausstattung des Heimarbeitsplatzes wie Monitor, Tastatur und Bürostuhl übernimmt die Firma bis zu einer Grenze von 800 Euro pro Person.` },
{ quelle: "spesenrichtlinie.md", text: `Dienstreisen müssen vor Antritt im Reisetool angemeldet werden. Die Firma erstattet Bahnfahrten in der 2. Klasse, Flüge nur bei Strecken über 600 Kilometer. Die Verpflegungspauschale beträgt 28 Euro pro vollem Reisetag. Belege sind innerhalb von 30 Tagen einzureichen.` },
{ quelle: "it-sicherheit.md", text: `Für den Zugriff auf Firmensysteme von unterwegs ist die Nutzung des VPN verpflichtend. Öffentliches WLAN darf nur über VPN verwendet werden. Jeder Account benötigt Zwei-Faktor-Authentifizierung. Verlorene oder gestohlene Geräte sind sofort der IT zu melden, damit der Fernzugriff gesperrt werden kann.` },
{ quelle: "weiterbildung.md", text: `Jede Mitarbeiterin und jeder Mitarbeiter hat ein jährliches Weiterbildungsbudget von 1.500 Euro. Damit lassen sich Konferenzen, Onlinekurse und Fachbücher finanzieren. Die Freigabe erfolgt durch die Teamleitung, sofern ein fachlicher Bezug zur Tätigkeit besteht.` },
];
function chunken(text: string, maxZeichen = 600): string[] {
const saetze = text.split(/(?<=[.!?])\s+/);
const chunks: string[] = [];
let aktuell = "";
for (const satz of saetze) {
if ((aktuell + " " + satz).length > maxZeichen && aktuell !== "") {
chunks.push(aktuell.trim());
aktuell = satz;
} else {
aktuell = aktuell === "" ? satz : aktuell + " " + satz;
}
}
if (aktuell.trim() !== "") chunks.push(aktuell.trim());
return chunks;
}
async function main() {
await qdrant.createCollection("wissensbasis-agentic", {
vectors: { size: 3072, distance: "Cosine" },
});
let id = 1;
for (const dokument of dokumente) {
for (const chunk of chunken(dokument.text)) {
const antwort = await client.embeddings.create({
model: "text-embedding-3-large",
input: chunk,
});
await qdrant.upsert("wissensbasis-agentic", {
wait: true,
points: [{ id, vector: antwort.data[0].embedding, payload: { text: chunk, quelle: dokument.quelle } }],
});
console.log(`Chunk ${id} aus ${dokument.quelle} gespeichert.`);
id = id + 1;
}
}
}
main().catch((fehler) => {
console.error(fehler);
process.exit(1);
});Nach npx tsx ingest-agentic.ts liegen fünf Chunks in der Collection, einer pro Dokument. Diese fünf Themen sind das Spielfeld, auf dem der Grader gleich unterscheiden muss, ob ein Treffer zur Frage passt oder nur zufällig ähnliche Wörter enthält.
Schritt 2: Suche und Bewertung als getrennte Bausteine
Agentic RAG lebt davon, dass die einzelnen Schritte eigenständige Funktionen sind, die die Schleife beliebig oft aufrufen kann. Der erste Baustein ist die Suche, technisch identisch zum klassischen RAG: Suchanfrage einbetten, in Qdrant die ähnlichsten Chunks holen. Neu ist, dass die Funktion den Score mit zurückgibt, denn beim Kalibrieren wollen Sie sehen, wie sicher ein Treffer ist. Die Konstante TOP_K steuert, wie viele Chunks pro Runde geholt werden:
const CHAT_MODELL = "gpt-5.4-mini";
const MAX_RUNDEN = 3;
const TOP_K = 3;
type Treffer = { text: string; quelle: string; score: number };
async function suche(suchanfrage: string): Promise<Treffer[]> {
const vektor = await client.embeddings.create({
model: "text-embedding-3-large",
input: suchanfrage,
});
const ergebnis = await qdrant.query("wissensbasis-agentic", {
query: vektor.data[0].embedding,
limit: TOP_K,
with_payload: true,
});
return ergebnis.points.map((p) => ({
text: String(p.payload?.text ?? ""),
quelle: String(p.payload?.quelle ?? ""),
score: p.score ?? 0,
}));
}Der zweite Baustein ist die Antwort-Funktion, ebenfalls wie im Grundlagen-Tutorial: Kontext aus den Treffern bauen, das Chat-Modell aus diesem Kontext antworten lassen, Quelle in Klammern. Der interessante dritte Baustein steht im nächsten Schritt: der Grader.
Schritt 3: Der Grader mit Structured Output
Der Grader ist das Herz der Schleife. Er bekommt die Frage und die gefundenen Treffer und liefert ein strukturiertes Urteil zurück: Reichen die Belege? Und falls nicht, wie sollte die nächste Suchanfrage lauten? Damit die Schleife diese Antwort zuverlässig weiterverarbeiten kann, erzwinge ich ein festes JSON-Format über response_format mit json_schema und strict: true. Azure OpenAI unterstützt Structured Outputs über die v1-API genauso wie OpenAI direkt, das habe ich mit gpt-5.4-mini geprüft:
type Urteil = {
ausreichend: boolean;
begruendung: string;
neue_suchanfrage: string;
};
async function bewerte(frage: string, treffer: Treffer[]): Promise<Urteil> {
const kontext = treffer
.map((t, i) => `[${i + 1}] (${t.quelle}) ${t.text}`)
.join("\n");
const antwort = await client.chat.completions.create({
model: CHAT_MODELL,
response_format: {
type: "json_schema",
json_schema: {
name: "beleg_urteil",
strict: true,
schema: {
type: "object",
additionalProperties: false,
properties: {
ausreichend: { type: "boolean" },
begruendung: { type: "string" },
neue_suchanfrage: { type: "string" },
},
required: ["ausreichend", "begruendung", "neue_suchanfrage"],
},
},
},
messages: [
{
role: "system",
content:
"Du bist ein Beleg-Prüfer in einem RAG-System. Setze ausreichend=true, sobald " +
"sich die Frage aus den Treffern beantworten lässt, auch wenn die Formulierung " +
"abweicht. Verlange keine wörtliche Übereinstimmung mit der Frage. Nur wenn die " +
"Treffer thematisch danebenliegen oder die nötige Information fehlt, setze " +
"ausreichend=false. Überlege dann, unter welchem Oberthema (etwa IT-Sicherheit, " +
"Spesen, Urlaub, Homeoffice, Weiterbildung) die Antwort im Handbuch stehen dürfte, " +
"und formuliere neue_suchanfrage aus dieser Perspektive, nicht nur mit Synonymen " +
"der ursprünglichen Frage.",
},
{
role: "user",
content: `Frage: ${frage}\n\nGefundene Treffer:\n${kontext}`,
},
],
});
return JSON.parse(antwort.choices[0].message.content ?? "{}") as Urteil;
}Zwei Formulierungen in diesem System-Prompt sind das Ergebnis von zwei Fehlversuchen, die ich in Schritt 6 zeige. Kurz vorweg: „Verlange keine wörtliche Übereinstimmung“ und „Überlege, unter welchem Oberthema die Antwort stehen dürfte“ stehen dort mit Absicht. Ohne die erste Zeile lief mein Grader ständig ins Leere, ohne die zweite drehte der Rewriter im Kreis.
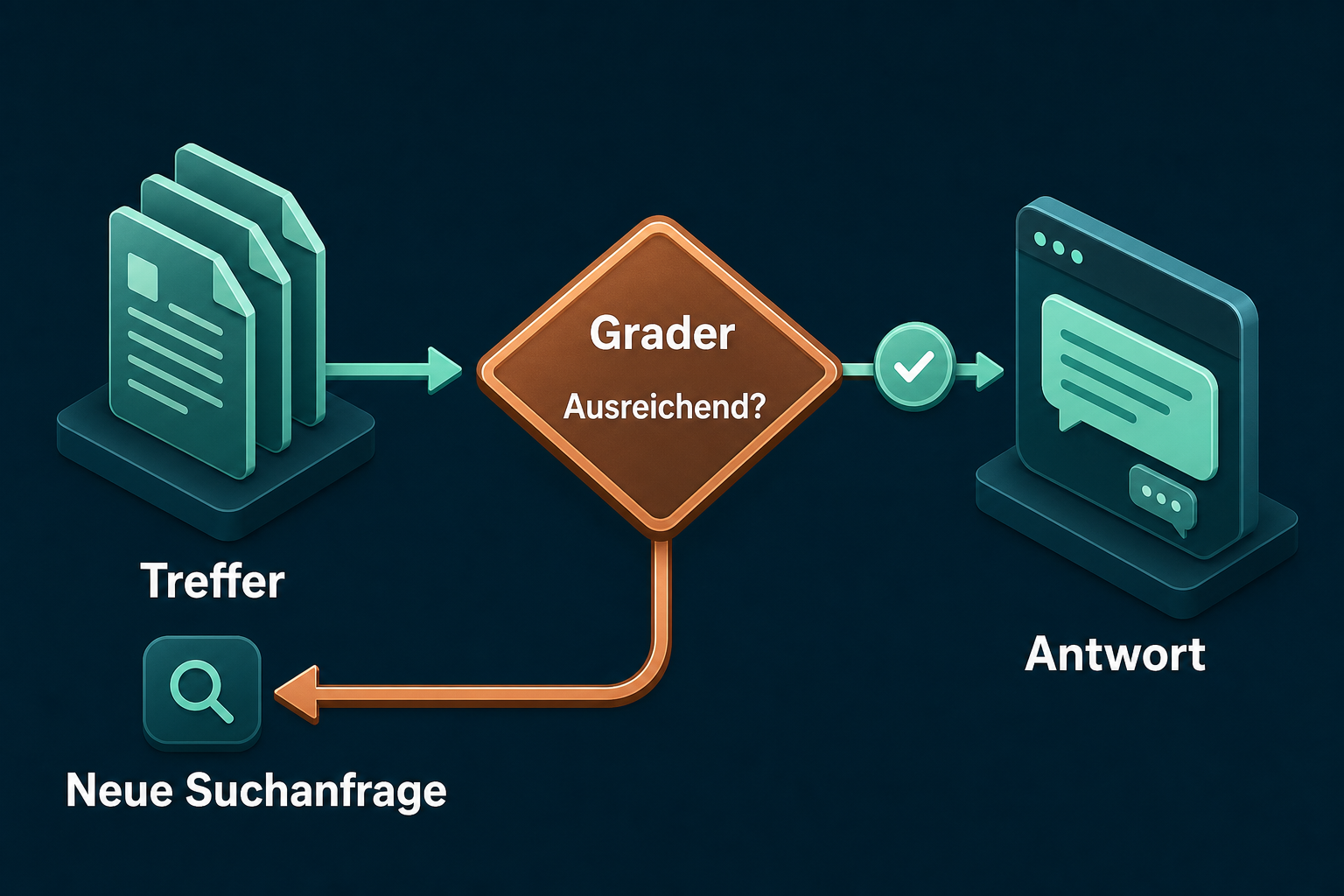
Schritt 4: Die Korrektur-Schleife zusammensetzen
Die Schleife sucht, lässt bewerten, und bei einem negativen Urteil übernimmt sie die vorgeschlagene neue Suchanfrage für die nächste Runde. Sie stoppt, sobald die Belege ausreichen, kein Rewrite mehr kommt, oder das Rundenlimit erreicht ist. Nur bei einem positiven Urteil wird geantwortet, sonst gibt es die ehrliche Absage:
async function main() {
const frage = process.argv[2] ?? "Wie viele Urlaubstage habe ich?";
let suchanfrage = frage;
let treffer: Treffer[] = [];
let urteil: Urteil | null = null;
for (let runde = 1; runde <= MAX_RUNDEN; runde++) {
treffer = await suche(suchanfrage);
urteil = await bewerte(frage, treffer);
console.log(`\nRunde ${runde}`);
console.log(` Suchanfrage: ${suchanfrage}`);
console.log(` Treffer: ${treffer.map((t) => `${t.quelle} (${t.score.toFixed(2)})`).join(", ")}`);
console.log(` Ausreichend: ${urteil.ausreichend}`);
console.log(` Begründung: ${urteil.begruendung}`);
if (urteil.ausreichend) break;
if (!urteil.neue_suchanfrage) break;
suchanfrage = urteil.neue_suchanfrage;
}
console.log("\nFrage: " + frage);
if (urteil?.ausreichend) {
console.log(`Antwort: ${await beantworte(frage, treffer)}`);
} else {
console.log("Antwort: Dazu finde ich nichts in der Wissensbasis.");
}
}Das Rundenlimit MAX_RUNDEN = 3 entscheidet über die Kostenkontrolle. Ohne eine harte Obergrenze kann eine agentische Schleife endlos weiterrewriten und Ihr Token-Budget verbrennen. Drei Runden sind für dieses Handbuch ein guter Startwert. Bei größeren Wissensbasen tarieren Sie den Wert gegen Ihre Kosten aus.
Schritt 5: Drei Verhalten in der Praxis beobachten
Als Nächstes beobachten Sie das Laufzeitverhalten. Ich habe drei Fragen durch die fertige Schleife geschickt, jede zeigt eine andere Seite von Agentic RAG.
Erstens die einfache Frage, deren Antwort direkt in einem Dokument steht:
npx tsx agentic-rag.ts "Wie viele Urlaubstage habe ich und was passiert mit Resturlaub?"Der Grader ist nach Runde 1 zufrieden, die Schleife endet sofort:
Runde 1
Suchanfrage: Wie viele Urlaubstage habe ich und was passiert mit Resturlaub?
Treffer: urlaubsrichtlinie.md (0.64), homeoffice-regelung.md (0.36), weiterbildung.md (0.36)
Ausreichend: true
Antwort: Du hast Anspruch auf 30 Urlaubstage pro Kalenderjahr. Resturlaub verfällt nicht automatisch, muss aber bis zum 31. März des Folgejahres genommen werden. (urlaubsrichtlinie.md)Wichtig dabei: Wenn das Retrieval gut ist, kostet die Schleife nur einen zusätzlichen Grader-Aufruf und verhält sich sonst wie klassisches RAG. Im Normalfall bleibt die Latenz praktisch gleich, der Zusatzaufwand fällt erst im Ausnahmefall an.
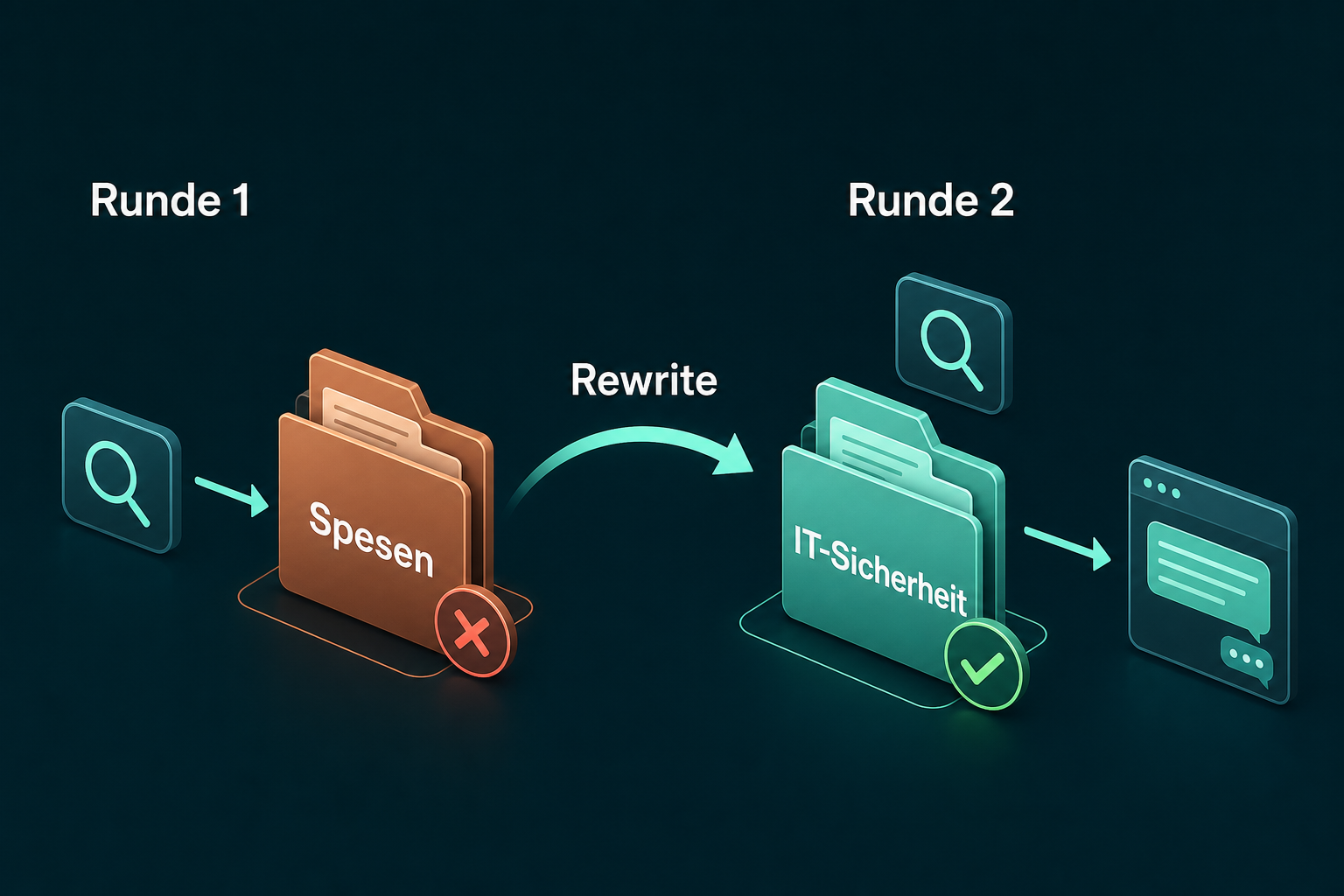
Zweitens der Ausnahmefall, in dem das erste Suchergebnis in die Irre führt. Damit die Rettung sichtbar wird, setze ich TOP_K = 1, hole also nur den besten Treffer. Die Frage klingt nach einer Reisefrage, die Antwort steht aber in der IT-Sicherheit:
npx tsx agentic-rag.ts "Auf der Bahnfahrt ist mir mein Laptop abhandengekommen, was jetzt?"Runde 1
Suchanfrage: Auf der Bahnfahrt ist mir mein Laptop abhandengekommen, was jetzt?
Treffer: spesenrichtlinie.md (0.37)
Ausreichend: false
Begründung: Der Treffer behandelt nur allgemeine Spesen- und Reiseabrechnungsregeln, aber nicht den Fall eines verlorenen Laptops.
Runde 2
Suchanfrage: Verlust oder Diebstahl von Arbeitsgeräten auf Dienstreisen ...
Treffer: spesenrichtlinie.md (0.49)
Ausreichend: false
Runde 3
Suchanfrage: Richtlinie zu verlorenen oder gestohlenen Arbeitsmitteln, Vorgehen bei abhandengekommenem Laptop im Zug
Treffer: it-sicherheit.md (0.51)
Ausreichend: true
Antwort: Melde den Verlust sofort der IT, damit der Fernzugriff gesperrt werden kann. (it-sicherheit.md)Hier sehen Sie den Kern von Agentic RAG bei der Arbeit. Runde 1 zieht das Spesen-Dokument, weil „Bahnfahrt“ und „Laptop“ oberflächlich nach Reise klingen. Der Grader erkennt, dass die Antwort dort nicht steht. Über zwei Umformulierungen löst sich der Rewriter vom Reise-Rahmen und trifft in Runde 3 die IT-Sicherheit. Ein klassisches RAG hätte in Runde 1 aus dem falschen Dokument geantwortet oder gepasst. Die Anzahl der Runden schwankt übrigens von Lauf zu Lauf, weil der Rewriter selbst ein Sprachmodell ist. Im einen Lauf genügt eine Umformulierung, im nächsten sind zwei nötig.
Drittens die Frage, deren Antwort schlicht nicht existiert. Das Handbuch sagt nichts über Betriebsrenten:
npx tsx agentic-rag.ts "Wie hoch ist die Betriebsrente nach 10 Jahren?"Die Schleife rewritet dreimal mit passendem Fachvokabular, findet aber nichts Passendes und gibt am Ende zu, dass sie nichts weiß, statt eine Zahl zu erfinden. Bei sensiblen Wissensbasen ist dieses Verhalten oft den Zusatzaufwand wert.
Schritt 6: Grader und Rewriter kalibrieren
Meine ersten beiden Versuche der Schleife scheiterten, und die Fehler sind lehrreicher als jeder funktionierende Code. Beide zeigen: Bei Agentic RAG entscheidet die Formulierung der Prompts über Erfolg und Endlosschleife.
Der erste Grader war zu streng. Ich hatte ihn angewiesen, die Frage „vollständig und eindeutig“ belegt zu prüfen. Bei der Café-Frage nach dem Zugriff auf Firmenmails fand er das richtige IT-Sicherheits-Dokument mit einem Score von 0,69, lehnte es aber drei Runden lang ab, weil der Wortlaut „Café am Bahnhof“ nicht wörtlich im Text stand. Am Ende behauptete das System, es finde nichts, obwohl die Antwort längst im Kontext lag. Der Fix war eine einzige Zeile: „Setze ausreichend=true, sobald sich die Frage beantworten lässt, auch wenn die Formulierung abweicht.“
Der zweite Fehler steckte im Rewriter. In der ersten Fassung schrieb er die Suchanfrage nur mit Synonymen der ursprünglichen Frage um. Bei der Laptop-im-Zug-Frage blieb er am Reise-Rahmen kleben und produzierte Anfragen wie „Fundbüro Reisegepäck Dienstreise“, die immer wieder das Spesen-Dokument zogen. Er fand die IT-Sicherheit nie. Erst der Zusatz, er solle überlegen, unter welchem Oberthema die Antwort im Handbuch stehen könnte, brachte den nötigen Perspektivwechsel.
Ein dritter Punkt ist keine Falle, sondern eine bewusste Entscheidung: TOP_K. Mit TOP_K = 3 und guten Embeddings landet das richtige Dokument bei einfachen Fragen fast immer schon in Runde 1 im Kontext, die Schleife rettet dann selten. Der Nutzen der Schleife wächst mit engem Retrieval, großen und lauten Korpora oder mehrstufigen Fragen. Die häufigsten Stolperfallen im Überblick:
| Fehler | Ursache | Lösung |
|---|---|---|
| Grader lehnt gute Treffer ab und läuft ins Leere | Grader verlangt wörtliche Übereinstimmung | Auf Beantwortbarkeit prüfen, nicht auf Wortgleichheit |
| Rewriter dreht im Kreis und findet das Zieldokument nie | Umformulierung bleibt am Wortlaut der Frage kleben | Rewriter zum Wechsel des Oberthemas anweisen |
| Kosten laufen aus dem Ruder | Keine harte Rundengrenze | MAX_RUNDEN setzen und gegen das Budget tarieren |
Cannot find name 'process' beim Typecheck | tsc kennt die Node-Typen nicht | @types/node installieren, beim direkten Aufruf --types node |
Was Sie jetzt haben und wie es weitergeht
Sie haben eine agentische RAG-Schleife aus vier Bausteinen: Suche, Grader mit Structured Output, Rewriter im selben Aufruf und Antwort. Das System korrigiert schwache Suchergebnisse selbst und sagt bei Wissenslücken ehrlich ab. Damit geht es über „einmal suchen, einmal antworten“ hinaus und prüft, ob seine Belege tragen.
Der Weg zum Produktivsystem hat mehrere Ausbaustufen, die dieses Tutorial bewusst offenlässt. Als Erstes fehlt ein vorgeschalteter Router, der einfache Faktfragen am teuren Loop vorbeischickt und nur komplexe Fragen in die volle Schleife lässt. Ergänzen sollten Sie außerdem Tracing ab Tag eins mit Langfuse oder OpenTelemetry, denn ohne Nachvollziehbarkeit ist eine Schleife eine Blackbox. Dazu gehört ein Eval-Set aus 30 bis 100 Referenzfragen inklusive Grenzfragen, gegen das Sie jede Prompt-Änderung am Grader messen. Und der rechtliche Rahmen: Je mehr Werkzeuge die Schleife nutzt, desto mehr Datenflüsse entstehen, was die DSGVO-Zweckbindung und die KI-Kennzeichnung nach Artikel 50 der KI-Verordnung berührt, die ab dem 02.08.2026 gilt.
Wie so ein System im Unternehmenskontext aussieht, beschreibe ich in RAG und Wissenssysteme. Den konzeptionellen Hintergrund zu Agentic RAG, CRAG und Self-RAG vertieft der Artikel Agentic RAG, und die strategische Einordnung, wann sich der Aufwand gegenüber klassischem RAG lohnt, finden Sie unter RAG-Systeme im Unternehmen.
FAQ
Häufige Fragen
Was ist der Unterschied zwischen klassischem RAG und Agentic RAG?
Klassisches RAG ist linear: Frage einbetten, Chunks suchen, aus den Chunks antworten. Agentic RAG schaltet zwischen Suche und Antwort ein Grading, das die Belege bewertet und die Suchanfrage bei Bedarf umformuliert. Dadurch entsteht eine Schleife, die schwache erste Treffer selbst korrigiert, statt aus ihnen zu antworten.
Wie viel teurer ist Agentic RAG als klassisches RAG?
Pro Runde kommt ein Grader-Aufruf und eventuell ein weiterer Embedding-Aufruf hinzu, im Erfolgsfall bei guter erster Suche also ein einziger zusätzlicher Modellaufruf. Bei einer schwierigen Frage mit mehreren Runden vervielfacht sich der Aufwand entsprechend der Rundenzahl. Als grobe Hausnummer liegt Agentic RAG damit beim Zwei- bis Dreifachen der Kosten von klassischem RAG, abhängig davon, wie oft die Schleife greift.
Brauche ich LangGraph oder ein Agenten-Framework dafür?
Nein. Dieses Tutorial nutzt eine schlichte for-Schleife und den Standard-OpenAI-Client, mehr braucht der Kern nicht. Frameworks wie LangGraph lohnen sich, wenn die Schleife verzweigt, mehrere Werkzeuge parallel nutzt oder ihren Zustand über viele Schritte hinweg verwalten muss. Für den Einstieg lenkt ein Framework eher vom Verständnis ab.
Warum liefert der Grader bei mir eine andere Rundenzahl?
Der Rewriter ist selbst ein Sprachmodell und formuliert die neue Suchanfrage jedes Mal etwas anders. Mal reicht ein Rewrite, mal braucht es zwei. Das ist normal. Wichtiger als die exakte Rundenzahl ist, dass die Schleife am Ende entweder belegt antwortet oder ehrlich absagt.
Funktioniert Structured Output mit Azure OpenAI genauso wie mit OpenAI direkt?
Ja. Über die v1-API von Azure OpenAI nutzen Sie denselben response_format-Parameter mit json_schema und strict: true wie bei OpenAI. Ich habe das mit gpt-5.4-mini geprüft, das Grader-Urteil kam bei jedem Aufruf als valides JSON zurück.